Can you Explain kNN in Ruby?
Hi again, everyone! The puffins and I had a few busy weeks since the last post, with lots of remote teaching, which for all of us is a bit challenging (see the two previous posts). But we still managed to do some cool, interesting stuff that we want to share with you. We definitely wanted to get back to some Ruby coding and especially showing students that there is more than just Python in data science. So, since I really enjoy looking under hoods, I decided to implement k-NN from scratch in Ruby and use it as a showcase in my lecture. There is also a interactive visualisation of the k-d-tree algorithm in the works, but more about that in another post. Plus a new PyData Dublin event coming up soon, so let’s get on with it …
Event Update
I’m so happy that PyData Dublin is back - with a vengeance! After a, pandemic caused, break, the wonderful and brilliant Siobhán Grayson (please make sure to follow her on Twitter: @siobhan_grayson) and I managed to organise a new meetup. We have very exciting international speaker, so make sure you register!
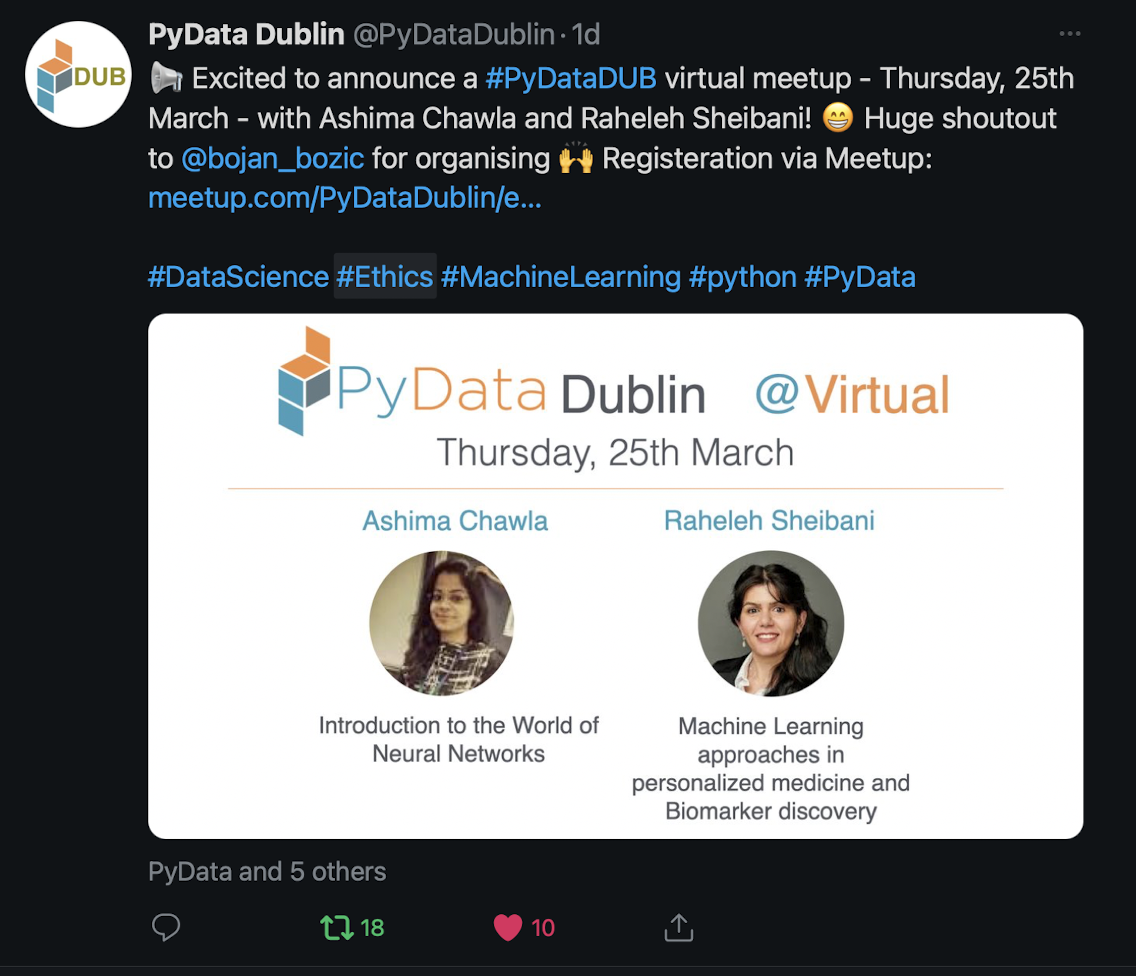 We will also have a virtual social event afterwards, better get your drink ready ;)
We will also have a virtual social event afterwards, better get your drink ready ;)
Similarity-based Learning
While similarity-based learning is one of the families of machine learning models that comes very natural to human understanding, you just need to find the most similar element and then predict the same as they had, right?, and it’s just like when you have a friend with similar taste as yourself, so if they order choc-mint ice cream, you can trust them and order it too. But then again, who doesn’t like choc-mint, right??? So … where was I? Oh, yeah similarity learning. It’s easy to understand how it works, but most people struggle to put it in code, so that’s why I decided to get you an example in Ruby. If you’re curious, about this and other Ruby code on similarity learning, check out my Github respository, you will only find the code I’m describing here right now, but it’s growing and will get some nice documentation and more similarity-theory code soon!
k-NN in Ruby
So let’s get down to the core of it. The beauty of Ruby code is that you can have straightforward implementations of maths formulas that are both aesthethically pleasing and easy to read (that’s not always the same thing for me :)). So here’s how that short piece of code looks like that implements k-NN in Ruby:
1
2
3
4
5
6
7
8
9
10
11
12
13
def knn(data_frame, k, query, distance_metric=:euclidean)
distances = []
data_frame.each :row do |x|
distances << euclidean(x.to_a[0...-1], query)
end
data_frame[:Distance] = distances
data_frame.sort!([:Distance])
return data_frame.first(k)[-2].mode
end
def euclidean(a, b)
return Math.sqrt([a,b].transpose.map {|x| (x.reduce :-)**2}.sum)
end
There is a really cool data analytics library for Ruby called Daru (Data Analysis in RUby). Now, I’m not using it directly in the piece of code above, it really is quite pure, but I do assume that the data_frame parameter is of type Daru::DataFrame. But let’s have a look at the knn function there. All it needs is the dataset as mention a Daru::DataFrame in the first parameter called data_frame, the k unsurprisingly stands for the number of neighbours we’re considering for our model, the query is the new instance we want to classify, and finally the distance_metric, we only support euclidean distance for now, so we can just ignore this parameter for the time being.
Once we get the function call and have all our parameters at hand, we can create an empty Array which is called distances as this is where we will store the list of euclidean distances for our query. Then we just loop through all rows of our data_frame and measure the distance to our query (more about that in a bit). Daru does a really good job in being user friendly, so all we have to do to create a new column in the data_frame is use its name as index and assign the Array. Remember, Ruby uses the colon to indicate an immutable string (often used as name for something). In the next step we sort the data_frame based on our calculated distances. I really love the ! in Ruby that applies the function on the object direcly without having to assign the result to a new object. Finally, all we have to do is take the first k rows, check their target feature values and return the mode as prediction. That’s it! Isn’t it elegant?
However, the best part is the one-liner in our euclidean function. It returns euclidean distance while showing off some of Ruby’s finest Array manipulation magic. So what we’re doing here is thake the two arrays (one of them is from our dataset, the other is the query), transpose them (meaning we take an element from each) and reduce by subtracting one from the other to get the difference. We square the difference and sum up the squares. All that’s left to do after that is taking the square root and return the result. All done!
Conclusion
Hope you share my enthusiasm for Ruby and appreciate the beauty of that code. Let me know what you think in the comments, especially if you don’t appreciate it at all or if you think I could or should have done something differently. But I hope you agree that it’s not such a bad demostration of the model and how easy it actually is to implement. I’m going to add more of it as I’m progressing and will also work on other model families, and the interactive k-d-tree example I promised earlier too, so stay tuned!
Let’s see what the puffins are up to …
Let me know what you think of this article on twitter @bojan_bozic!